Taxonomy of my bullet points
\( \textcolor{red}{\mathbf{>}} \) (Property)
\( \textcolor{red}{\#} \) (Definition)
\( \textcolor{red}{\bullet} \) (Topic)
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}} \) (Observation)
\( \textcolor{red}{\color{red}{\boldsymbol{*}}} \) (Example)
\( \textcolor{red}{\color{red}{\boldsymbol{|}}} \) (Algorithm)
\(\color{red} \textbf{\#} \) SELECT: It selects tables
Giving alias
1
|
SELECT field AS alias; -- equivalent to alias = field
|
Aggregating:
1
|
SELECT COUNT(id), SUM(quantity), AVG(age); -- aggregators
|
Min-Max aggregators:
1
|
SELECT MIN(data), MAX(quantity);
|
If you want to add columns to the complete table:
1
|
SELECT my_table.*, COUNT(my_table.column) FROM my_table
|
\(\color{red} \textbf{\#} \) FROM: Calls the table that is going to be considered as a source.
1
2
|
SELECT *
FROM base_de_datos.tabla
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) SQL sentences are not case-sensitive, but it is recommended to put those keywords in uppercase. To make them stand out.
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\)
JOIN is a great compyearn of FROM.
\( \textcolor{red}{\bullet}\) Remote: Allows you to obtain information on a remote database. To obtain information from a remote table you can use dblink. Said function takes two parameters:
- Set up the connection to the remote DBMS
- Make SQL queries
\( \textcolor{red}{\color{red}{\boldsymbol{*}}} \) dblink
1
2
3
4
5
6
7
8
9
10
11
12
|
SELECT *
FROM dblink('
dbname=somedb
port=5432 host=someserver
user=someuser
password=somepwd',
'SELECT gid, area, parimeter,
state, country,
tract, blockgroup,
block, the_geom
FROM massgis.cens2000blocks')
AS blockgroups
|
The process of choosing which columns (or expressions) a query must return is called a projection.
The selection means, the elements from the projection we are going to pick.
Let’s suppose the next query:
1
2
|
SELECT Column1, Column2, Column3
FROM table_1 WHERE Column3=False;
|
The projection will be: Column1, Column2 and Column3. And the selection is Column3=False.
So we can generally express:
1
|
SELECT (Projection expression) WHERE (Selection expression);
|
The most basic query would be:
The asterisk (*) is a wildcard that let us bring the complete projection (Every single field on the table)
\( \textcolor{red}{\#} \) ALIAS (AS):
An alternative way of calling a tabla or column. It helps to shorten querys.
1
|
SELECT Columna1 AS Alias1 FROM Tabla1;
|
On aggregation
\( \textcolor{red}{\#} \) Aggregation functions:
-
COUNT: it returns the total number of rows selected in the query, in particular COUNT(*) will count the total records. Including the ones with nulls.
-
MIN: returns the minimum value of the specified field.
-
MAX: returns the maximum value of the specified field.
-
SUM: sums the values of the specified fields. For numeric fields only.
-
AVG: returns the average of values of the specified fields. For numeric fields only.
\( \textcolor{red}{\#} \) IF():
function that evaluates an expression and returns result_true when the expression is True and result_false when the expression is False.
1
|
IF (expression, result_true, result_else)
|
\( \textcolor{red}{\#} \) CASE():
Evaluates a list of conditions and returns one or multiple possible results.
Starts with the CASE sentence, then it evaluates the expressions started with WHEN and in case it’s true, it will return the specified result for the condition after the THEN keyword.
The ELSE sentence is optional and it will return this value in case of all the conditions WHEN before are False.
If all conditions are False, and the clause ELSE does not exist, NULL will be returned.
1
2
3
4
5
6
7
|
CASE
WHEN eval_1 THEN result_1
WHEN eval_2 THEN result_2
...
WHEN value_n THEN result_n
ELSE result
END AS valueResult;
|
Some examples
All records
1
|
SELECT * FROM EXAMS.students;
|
Alias
1
2
3
|
SELECT nombre as "name",
apellido as "last name"
FROM EXAMS.students;
|
Counting
1
2
|
SELECT COUNT(id)
FROM EXAMS.students;
|
Sum
1
2
|
SELECT SUM(fellowship)
FROM EXAMS.students;
|
Average
1
2
|
SELECT AVG(fellowship)
FROM EXAMS.students;
|
Mínimum
1
2
|
SELECT MIN(fellowship)
FROM EXAMS.students;
|
Maximum
1
2
|
SELECT MAX(fellowship)
FROM EXAMS.students;
|
Case
1
2
3
4
5
6
7
8
9
|
SELECT nombre,
apellido,
fellowship,
CASE
WHEN (fellowship > 4000) THEN 'Greater than 4000'
WHEN (fellowship = 2000) THEN 'Equal to 2000'
ELSE 'Greater than 2000 and less than 4000'
END cost
FROM EXAMS.students;
|
Joins
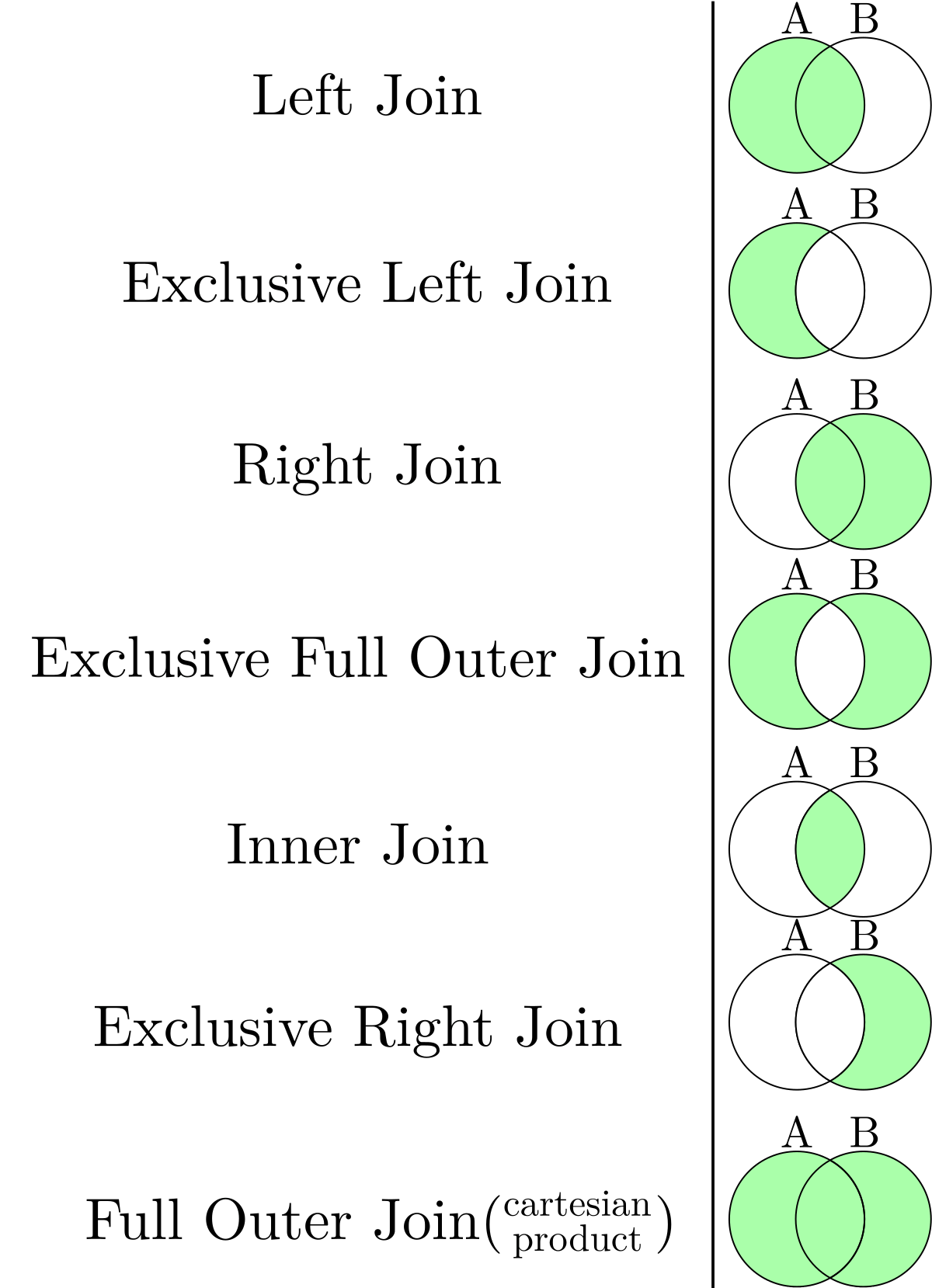
\( \textcolor{red}{\#} \) JOIN:
1
2
3
4
|
SELECT *
FROM daily_table AS td
JOIN monthly_table AS tm
ON td.pk = tm.fk;
|
\( \textcolor{red}{\#} \) WHERE:
1
|
SELECT * FROM daily_table WHERE id = 1;
|
1
2
|
SELECT * FROM daily_table
WHERE quantity > 10;
|
1
2
|
SELECT * FROM daily_table
WHERE quantity < 100;
|
1
2
3
|
SELECT * FROM daily_table
WHERE quantity > 10
AND quantity < 100;
|
1
2
3
|
SELECT * FROM daily_table
WHERE quantity > 10
AND quantity < 100;
|
1
2
3
|
SELECT * FROM daily_table
WHERE quantity
BETWEEN 10 AND 100;
|
1
2
3
4
5
6
7
|
SELECT * FROM users
WHERE name = "Israel"
AND (
lastname = "Vázquez"
OR
lastname = "López"
);
|
1
2
3
4
|
SELECT * FROM users
WHERE name = "Israel"
AND lastname = "Vázquez"
OR lastname = "López";
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) The % character is SQL regex wildcard
1
2
|
SELECT * FROM users
WHERE name LIKE "Is%";
|
$$
\begin{array}{c|l|c|l}
& \text{Description} & e.g. & \text{Examples Matches} \\ \hline
\hat{ } & \text{match beginning of string} & \hat{ }c \% & \text{cat-car-chain} \\
| & \text{OR} & c(a|o) \% & \text{can-corn-cop} \\
\_ & \text{char(LIKE/SIMILAR TO)} & c\_ & \text{co-fico-pico} \\
\% & \text{string(LIKE/SIMILAR TO)} & c\% & \text{chart-articulation-crate} \\
. & \text{char(POSIX)} & c. & \text{co-fico-pico} \\
.* & \text{string (POSIX)} & c.* & \text{chart-articulation-crate} \\
+ & \text{Repet. prev. item one} + \text{times} & co+ & \text{coo-cool} \end{array}
$$
1
2
|
SELECT * FROM users
WHERE name LIKE "Is_ael";
|
1
2
|
SELECT * FROM users
WHERE name NOT LIKE "Is_ael";
|
1
2
|
SELECT * FROM users
WHERE name IS NULL;
|
1
2
|
SELECT * FROM users
WHERE name IS NOT NULL;
|
1
2
|
SELECT * FROM users
WHERE name IN ('Israel', 'Laura', 'Luis');
|
\( \textcolor{red}{\#} \) ORDER BY:
It is ascending by default on postgresql
1
|
SELECT * FROM daily_table ORDER BY fecha;
|
1
2
|
SELECT * FROM daily_table
ORDER BY fecha ASC;
|
1
2
|
SELECT * FROM daily_table
ORDER BY fecha DESC;
|
\( \textcolor{red}{\#} \) GROUP BY: will condense into a single row all selected rows that share the same values for the grouped
expressions.
1
2
3
4
|
SELECT tutor_id, sum(fellowship)
FROM college.students
GROUP BY tutor_id
ORDER BY tutor_id;
|
\( \textcolor{red}{\#} \) LIMIT:
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) This is really useful
because it saves computational power,
no need to process all
1
|
SELECT * FROM daily_table LIMIT 1500;
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) You can get rows in the ordinal interval [offset, offset + limit]
1
2
|
SELECT * FROM daily_table
OFFSET 1500 LIMIT 1500;
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) OFFSET:
Select the row from which it will start printing records.
Challenges I
\( \textcolor{red}{\bullet}\) CHALLENGE, The first:
Take the first 5 rows:
1
2
|
SELECT * FROM college.students
FETCH FIRST 5 ROWS ONLY;
|
1
2
|
SELECT * FROM college.students
WHERE id BETWEEN 1 AND 5;
|
1
|
SELECT * FROM college.students LIMIT 5;
|
1
2
|
SELECT * FROM college.students
WHERE id in (1,2,3,4,5);
|
1
2
3
4
5
6
|
SELECT *
FROM (
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
) AS students_with_rows
WHERE row_id in (1,2,3,4,5);
|
1
2
3
4
5
6
|
SELECT *
FROM (
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
) AS students_with_rows
WHERE row_id <= 5;
|
\( \textcolor{red}{\bullet}\) The second larger
First, show the largest 5
1
2
|
SELECT * FROM college.students
ORDER BY fellowship DESC LIMIT 5;
|
The second highest
1
2
3
4
|
SELECT DISTINCT fellowship FROM
college.students
ORDER BY fellowship DESC
OFFSET 1 LIMIT 1;
|
Crazy
The query returns all employees whose Salary is higher than 2 other salaries. The parentheses is misleading and isn’t needed.
1
2
3
4
5
6
7
|
SELECT * FROM employee e
--this space has an implicit as--
WHERE 2 = (
SELECT COUNT(DISTINCT(e1.sal))
FROM employee e1
WHERE e.sal > e1.sal
);
|
For the college example
1
2
3
4
5
6
|
SELECT * FROM college.students AS a
WHERE 2=(
SELECT COUNT(DISTINCT a1.fellowship)
FROM college.students AS a1
WHERE a1.fellowship >= a.fellowship
);
|
An alternative:
1
2
3
4
5
6
7
8
9
10
11
12
|
-- count per join between tables
SELECT DISTINCT fellowship
FROM college.students a1
WHERE 2=(
-- take the second greatest
SELECT COUNT(DISTINCT fellowship)
FROM college.students a2
WHERE a1.fellowship<=a2.fellowship
) -- the subquery could have a name
-- something, how many different values
-- greater than every elemento of a2
;
|
How it works:
\( \textcolor{red}{\bullet}\) Explanation:
Inside of the subquery there is a comparison between two copies of the same column, for example:
1
2
3
4
|
a1.fellowship = [2000, 4800, 1000, 5000, 3000]
-- Disctinct
a2.fellowship = [2000, 4800, 1000, 5000, 3000]
-- Distinct
|
For each value, get all it’s possible greater values
1
2
3
4
5
|
2000 -> 3000, 5000, 4800, 2000
4800 -> 5000, 4800
1000 -> 3000, 5000, 4800, 2000, 1000
5000 -> 5000
3000 -> 3000, 5000, 4800
|
Finally count them up
1
2
|
fellowship = [2000, 4800, 1000, 5000, 3000]
count = [4, 2, 5, 1, 3]
|
This gets translated to an indexed order, this is why picking the 2 will give us the second greates fellowship value. This method is really slow. It requires \(n^2\) steps (\(n\) comparison for every \(n\) value) while the sorting takes \(n \log(n)\) steps.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
-- With limit --
SELECT DISTINCT fellowship, tutor_id
FROM college.students
WHERE tutor_id = 20
ORDER BY fellowship DESC
LIMIT 1 OFFSET 1;
-- Count per join between tables --
SELECT DISTINCT fellowship
FROM college.students a1
WHERE 2=(
SELECT COUNT(DISTINCT fellowship)
FROM college.students a2
WHERE a1.fellowship<=a2.fellowship
);
-- Join with subquery --
SELECT *
FROM college.students AS data_students
INNER JOIN (
SELECT DISTINCT fellowship
FROM college.students
WHERE tutor_id = 20
-- dont get it works the same
ORDER BY fellowship DESC
LIMIT 1 OFFSET 1
) AS second_greatest_fellowship
ON data_students.fellowship
= second_greatest_fellowship.fellowship;
-- Subquery en Where --
SELECT *
FROM college.students AS data_students
WHERE fellowship = (
SELECT DISTINCT fellowship
FROM college.students
WHERE tutor_id = 20
ORDER BY fellowship DESC
LIMIT 1 OFFSET 1
);
|
\( \textcolor{red}{\color{red}{\boldsymbol{*}}} \) How to take the second half of a table:
1
2
3
4
5
|
SELECT * FROM college.students
OFFSET (
SELECT (COUNT(id)/2)
FROM college.students
);
|
In this case I use create view
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE view garbage AS
SELECT * FROM college.students AS data_students
WHERE fellowship = (
SELECT DISTINCT fellowship
FROM college.students
WHERE tutor_id = 20
ORDER BY fellowship DESC
LIMIT 1 OFFSET 1
);
SELECT * FROM garbage OFFSET (
SELECT (count(id)/2) FROM garbage
);
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) 2nd half of the table
1
2
3
4
5
6
|
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
OFFSET (
SELECT COUNT(*)/2
FROM college.students
);
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) 2nd half of the table, alternative
1
2
3
4
5
6
|
SELECT *
FROM college.students
OFFSET (
SELECT COUNT(*)/2
FROM college.students
);
|
\( \textcolor{red}{\bullet}\)
Select a set of options
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- -- Select results in a set
-- In array --
SELECT *
FROM (
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
) AS students_with_row_numa
WHERE row_id IN (1,2,3,4,5);
-- IN with subquery --
SELECT *
FROM college.students
WHERE id IN (
SELECT id
FROM college.students
WHERE tutor_id = 30
);
|
\( \textcolor{red}{\bullet}\) RETO:
Get every studendt, except those with all tutor_id columns different from 30
1
2
3
4
5
6
7
|
SELECT *
FROM college.students
WHERE id IN (
SELECT id
FROM college.students
WHERE tutor_id < 30 OR tutor_id > 30
);
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\)
Or you can use != or <> both cases are better than this overengineered thing
\( \textcolor{red}{\bullet}\) Back in my days
1
2
3
4
5
6
7
8
9
10
|
-- -- Extract parts of a date
-- Con EXTRACT --
SELECT EXTRACT(YEAR FROM date_inscription)
AS year_inscription
FROM college.students;
-- Con DATE_PART --
SELECT DATE_PART('YEAR', date_inscription)
AS year_inscription
FROM college.students;
|
1
2
3
4
5
6
7
|
SELECT DATE_PART('YEAR', date_inscription)
AS year_inscription,
DATE_PART('MONTH', date_inscription)
AS mes_inscription,
DATE_PART('DAY', date_inscription)
AS dia_inscription
FROM college.students;
|
\( \textcolor{red}{\bullet}\) Challenge:
Extract the fields of a date
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- Extract --
SELECT EXTRACT(HOUR FROM date_inscription)
AS hora_inscription,
EXTRACT(MINUTE FROM date_inscription)
AS minuto_inscription,
EXTRACT(SECOND FROM date_inscription)
AS segundo_inscription
FROM college.students;
-- Date_Part --
SELECT DATE_PART('HOUR', date_inscription)
AS hora_inscription,
DATE_PART('MINUTE', date_inscription)
AS minuto_inscription,
DATE_PART('SECOND', date_inscription)
AS segundo_inscription
FROM college.students;
|
\( \textcolor{red}{\bullet}\) Select by year
1
2
3
4
5
6
7
8
9
10
11
12
|
-- -- Filter students inscripted in 2019
-- Filtro EXTRACT --
SELECT *
FROM college.students
WHERE (
EXTRACT(YEAR FROM date_inscription)
) = 2019;
-- Filtro DATE_PART --
SELECT *
FROM college.students
WHERE (DATE_PART('YEAR', date_inscription)) = 2019;
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) Another solution
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- Filter subquery DATE_PART --
SELECT *
FROM (
SELECT *,
DATE_PART('YEAR', date_inscription)
AS year_inscription,
DATE_PART('MONTH', date_inscription)
AS mes_inscription
FROM college.students
) AS students_con_year_mes
WHERE year_inscription = 2019
AND mes_inscription = 5;
-- alternative--
SELECT *
FROM college.students
WHERE (DATE_PART('YEAR', date_inscription)) = 2019
and (DATE_PART('MONTH', date_inscription)) = 5;
|
\( \textcolor{red}{\bullet}\) Duplicates
Insert this one:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
INSERT INTO college.students (
id,
nombre,
apellido,
email,
fellowship,
date_inscription,
career_id,
tutor_id)
VALUES (
1001,
'Pamelina',
NULL,
'pmylchreestrr@salon.com',
4800,
'2020-04-26 10:18:51',
12,
16)
|
1
2
3
4
5
6
7
8
9
|
-- -- Delete duplicated registers
-- Subquery by id --
SELECT *
FROM college.students ou
WHERE (
SELECT COUNT(*)
FROM college.students inr
WHERE inr.id = ou.id
) > 1;
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) :: is an alias of CAST
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
-- Hash text --
-- another way, all the row
SELECT (college.students.*)::text, COUNT(*)
FROM college.students
GROUP BY college.students.*
HAVING COUNT(*) > 1;
-- Hash excluding ID --
SELECT (
college.students.nombre,
college.students.apellido,
college.students.email,
college.students.fellowship,
college.students.date_inscription,
college.students.career_id,
college.students.tutor_id
)::text, COUNT(*)
FROM college.students
GROUP BY college.students.nombre,
college.students.apellido,
college.students.email,
college.students.fellowship,
college.students.date_inscription,
college.students.career_id,
college.students.tutor_id
HAVING COUNT(*) > 1;
-- Partición all fields except ID
SELECT *
FROM (
SELECT id,
ROW_NUMBER() OVER(
PARTITION BY
nombre,
apellido,
email,
fellowship,
date_inscription,
career_id,
tutor_id
ORDER BY id asc
) AS row,
*
FROM college.students
) duplicates
WHERE duplicates.row > 1;
|
\( \textcolor{red}{\bullet}\) Solved Challenge:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
DELETE FROM college.students
WHERE id IN
(
SELECT id
FROM (
SELECT id,
ROW_NUMBER() OVER(
PARTITION BY
nombre,
apellido,
email,
fellowship,
date_inscription,
career_id,
tutor_id
ORDER BY id asc
) AS row
FROM college.students
) duplicates
WHERE duplicates.row > 1
);
|
Ranges
\( \textcolor{red}{\bullet}\) Range selectors:
$$
\begin{array}{l|l|l|l}
& \text{Description} & Example & Result \\ \hline
= & \text{equal} & ARRAY{[}1.1,2.1,3.1{]}::int{[}{]} = ARRAY{[}1,2,3{]} & t \\
< > & \text{not equal} & ARRAY{[}1,2,3{]} < > ARRAY{[}1,2,4{]} & t \\
< & \text{less than} & ARRAY{[}1,2,3{]} < ARRAY{[}1,2,4{]} & t \\
> & \text{greater than} & ARRAY[1,4,3] > ARRAY[1,2,4] & t \\
< = & \text{less than or equal} & ARRAY{[}1,2,3{]} < = ARRAY{[}1,2,3{]} & t \\
>= & \text{greater than or equal} & ARRAY{[}1,4,3{]} >= ARRAY{[}1,4,3{]} & t \\
@> & \text{contains} & ARRAY{[}1,4,3{]} @> ARRAY{[}3,1,3{]} & t \\
< @ & \text{is contained by} & ARRAY{[}2,2,7{]} < @ ARRAY{[}1,7,4,2,6{]} & t \\
|| & \text{array2array concat} & ARRAY{[}1,2,3{]} || ARRAY{[}4,5,6{]} & \lbrace 1,2,3,4,5,6 \rbrace \\
|| & \text{array2array concat} & ARRAY{[}1,2,3{]} || ARRAY{[}{[}4,5,6{]},{[}7,8,9{]}{]} & \lbrace \lbrace 1,2,3 \rbrace,\lbrace 4,5,6 \rbrace,\lbrace 7,8,9 \rbrace \rbrace \\
|| & \text{element2array concat} & 3 || ARRAY{[}4,5,6{]} & \lbrace 3,4,5,6 \rbrace \\
|| & \text{array2element concat} & ARRAY[4,5,6] || 7 & \lbrace 4,5,6,7 \rbrace \end{array}
$$
\( \textcolor{red}{\#} \texttt{int4range} \) - Range of integer
\( \textcolor{red}{\#} \texttt{int8range} \) - Range of bigint
\( \textcolor{red}{\#} \texttt{numrange} \) - Range of numeric
\( \textcolor{red}{\#} \texttt{tsrange} \) - Range of timestamp without time zone
\( \textcolor{red}{\#} \texttt{tstzrange} \) - Range of timestamp with time zone
\( \textcolor{red}{\#} \texttt{daterange} \) - Range of date
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- Initial examples
SELECT *
FROM college.students
WHERE tutor_id IN (11,12,13,14,15,16,17,18,19,20);
SELECT *
FROM college.students
WHERE tutor_id >= 1
AND tutor_id <= 10;
SELECT *
FROM college.students
WHERE tutor_id BETWEEN 1 AND 10;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
-- In range? --
SELECT int4range(10, 20) @> 3;
-- Overlap? --
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
-- Upper limit --
SELECT upper(int8range(15, 25));
-- Intersection --
SELECT int4range(10, 20) * int4range(15, 25);
-- is empty?
SELECT isempty(numrange(1, 5));
-- Filter students with tutor_id between 1 and 10 --
SELECT *
FROM college.students
WHERE int4range(10, 20) @> tutor_id;
|
Challenges II
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) Challenge intersection between tutor_id y career_id.
1
|
select tutor_id * career_id from college.students;
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) CHALLEGNE, numbers in commmon between tutor_id and career_id
1
2
3
4
5
6
7
|
SELECT numrange(
(SELECT min(tutor_id) FROM college.students),
(SELECT max(tutor_id) FROM college.students)
) * numrange(
(SELECT min(career_id) FROM college.students),
(SELECT max(career_id) FROM college.students)
);
|
\( \textcolor{red}{\bullet}\) You are the greatest
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- Maximum value of the table --
SELECT date_inscription
FROM college.students
ORDER BY date_inscription DESC
LIMIT 1;
-- trying trough GROUP BY --
SELECT career_id, date_inscription
FROM college.students
GROUP BY career_id, date_inscription
ORDER BY date_inscription DESC;
-- MAX --
SELECT career_id, MAX(date_inscription)
FROM college.students
GROUP BY career_id
ORDER BY career_id;
|
\( \textcolor{red}{\bullet}\)
Challenge mínimum nombre, by tutor_id
1
2
3
4
|
SELECT min(nombre), tutor_id
FROM college.students
GROUP BY tutor_id
ORDER BY tutor_id;
|
\( \textcolor{red}{\bullet}\) Selfish
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
-- Relation student / tutor --
SELECT a.nombre,
a.apellido,
t.nombre,
t.apellido
FROM college.students AS a
INNER JOIN college.students AS t
ON a.tutor_id = t.id;
-- Concat text operation --
SELECT CONCAT(a.nombre, ' ', a.apellido)
AS alumno,
CONCAT(t.nombre, ' ', t.apellido)
AS tutor
FROM college.students AS a
INNER JOIN college.students
AS t ON a.tutor_id = t.id;
-- Counting students per tutor --
SELECT CONCAT(t.nombre, ' ', t.apellido)
AS tutor,
COUNT(*) AS students_by_tutor
FROM college.students AS a
INNER JOIN college.students AS t
ON a.tutor_id = t.id
GROUP BY tutor
ORDER BY students_by_tutor DESC
LIMIT 5;
|
\( \textcolor{red}{\bullet}\) CHALLENGE: Average students per tutor
1
2
3
4
5
6
7
8
9
|
Select AVG(students_by_tutor) as average_per_tutor
from (
SELECT CONCAT(t.nombre, ' ', t.apellido) AS tutor,
COUNT(*) AS students_by_tutor
FROM college.students AS a
INNER JOIN college.students AS t ON a.tutor_id = t.id
GROUP BY tutor
ORDER BY students_by_tutor DESC)
as tutor_students_by_tutor;
|
\( \textcolor{red}{\bullet}\) Solving differences
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
-- Students per career --
SELECT career_id, count(*) AS cuenta
FROM college.students
GROUP BY career_id
ORDER BY cuenta DESC;
-- Delete careers with ids between 30 and 40 --
DELETE FROM college.carreras
WHERE id BETWEEN 30 AND 40;
-- Exlusive left join --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
LEFT JOIN college.carreras AS c
ON a.career_id = c.id
WHERE c.id IS NULL;
|
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) CHALLENGE: Select registers from both tables, no matter if there is a match.
1
2
3
4
5
6
7
8
9
|
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
FULL OUTER JOIN college.carreras AS c
ON a.career_id = c.id
ORDER BY a.career_id DESC, c.id DESC;
|
\( \textcolor{red}{\bullet}\) All the JOINS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
-- Left Join Exclusive: Intersection --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
LEFT JOIN college.carreras AS c
ON a.career_id = c.id
WHERE c.id IS NULL
order by a.career_id DESC;
-- Left Join --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
LEFT JOIN college.carreras AS c
ON a.career_id = c.id
-- ORDER BY c.id DESC
order by a.career_id DESC;
-- Right Join Exclusive: Intersection --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
RIGHT JOIN college.carreras AS c
ON a.career_id = c.id
WHERE a.id IS NULL
ORDER BY c.id;
-- Right Join --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
RIGHT JOIN college.carreras AS c
ON a.career_id = c.id
ORDER BY c.id DESC;
-- Inner Join: Cartesian product --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
INNER JOIN college.carreras AS c
ON a.career_id = c.id
ORDER BY c.id DESC;
-- Simetric difference --
SELECT a.nombre,
a.apellido,
a.career_id,
c.id,
c.carrera
FROM college.students AS a
FULL OUTER JOIN college.carreras AS c
ON a.career_id = c.id
ORDER BY a.career_id DESC, c.id DESC;
|
\( \textcolor{red}{\bullet}\) Triangulation
Generate a triangle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
-- Funcition lpad --
SELECT lpad('sql', 15, '*');
-- Incremental Lpad --
SELECT lpad ('sql', id, '*')
FROM college.students
WHERE id < 10;
-- Triangle with Lpad --
SELECT lpad ('*', id, '*')
FROM college.students
WHERE id < 4;
-- Messing with the triangle --
SELECT lpad ('*', id, '*')
FROM college.students
WHERE id < 10
ORDER BY career_id;
-- Table with row_id --
SELECT *
FROM (
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
) AS students_with_row_num
WHERE row_id <= 5;
-- lpad with row_id --
SELECT lpad('*', CAST (row_id AS int), '*')
FROM (
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
) AS students_with_row_num
WHERE row_id <= 10;
-- Reordering lpad with row_id --
SELECT lpad('*', CAST (row_id AS int), '*')
FROM (
SELECT ROW_NUMBER() OVER() AS row_id, *
FROM college.students
) AS students_with_row_num
WHERE row_id <= 10;
|
\( \textcolor{red}{\bullet}\) Generando rangos
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
-- Generate a series from 1 to 4 --
SELECT *
FROM generate_series(1,4);
-- Generate a series from 5 to 1 with steps of two --
SELECT *
FROM generate_series(5,1,-2);
-- Generate an array with 0 tuples --
SELECT *
FROM generate_series(3,4);
SELECT *
FROM generate_series(4,3);
SELECT *
FROM generate_series(4,4);
SELECT *
FROM generate_series(3,4,-1);
-- Series from 1.1 to 4 or less with steps 1.3 --
SELECT generate_series(1.1, 4, 1.3);
-- Generate a sequence of dates from
-- today with a separation of
-- 7 days (1 week)
-- With the + operator for dates
SELECT current_date + s.a AS dates
FROM generate_series(0,14,7) AS s(a);
-- Generate a sequence with stepes of 10 hours --
SELECT * FROM generate_series(
'2020-09-01 00:00'::timestamp,
'2020-09-04 12:00', '10 hours');
-- Join with sequence --
SELECT a.id,
a.nombre,
a.apellido,
a.career_id,
s.a
FROM college.students AS a
INNER JOIN generate_series(0,10) AS s(a)
ON s.a = a.career_id
ORDER BY a.career_id;
|
\( \textcolor{red}{\bullet}\) CHALLENGE: Create the triangle using a generate_series.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- cast varchar
SELECT rpad(cast(p as varchar), p, '*')
FROM generate_series(0,10,1) as p;
SELECT generate_series(0,10,1) as p,
generate_series(1,11,1) as b;
SELECT p, b
FROM generate_series(0,10,1) AS p
FULL JOIN
generate_series(1,11,1) AS b
ON p=b
WHERE p is null or b is null;
|
\( \textcolor{red}{\bullet}\) Regular expressions
1
2
3
4
5
6
7
8
9
|
SELECT email
FROM college.students
WHERE
email ~*'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}';
SELECT email
FROM college.students
WHERE
email ~*'[A-Z0-9._%+-]+@google[A-Z0-9.-]+\.[A-Z]{2,4}';
|
Window function
\( \textcolor{red}{\#} \) Window function: Do calculations in tuples
related to the current tuple.
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) It lets you avoid the use of self-joins and reduces complexity around analytics, aggregation, and cursors.
Partition by
\( \textcolor{red}{\color{red}{\boldsymbol{\sim}}}\) PARTITION BY:
Depending on what you need, you can use a PARTITION BY in our queries to calculate aggregated values on the defined groups. The PARTITION BY is combined with OVER() and window functions to calculate aggregated values. Similar to GROUP BY and aggregate functions, but with one difference: when you use PARTITION BY, the row-level details are preserved and not collapsed. You get the original row-level data and the aggregated values at your disposal. You can also use all aggregate functions as window functions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
-- Average fellowship by carrera
SELECT *,
AVG(fellowship)
OVER (PARTITION BY career_id)
FROM college.students;
-- If a partition is not specified we take
-- all info from the table
SELECT *,
AVG(fellowship) OVER ()
FROM college.students;
-- Get the sum of fellowships increasingly ordered
-- with ORDER BY we take all the values
-- sorted before or after the current tuple
SELECT *,
SUM(fellowship)
OVER (ORDER BY fellowship)
FROM college.students;
-- Get the sum of fellowships per carrer
-- sorted in increasing order --
SELECT *,
SUM(fellowship)
OVER (
PARTITION BY career_id
ORDER BY fellowship)
FROM college.students;
-- Get the index of the current tuple in the frame of career
-- in decreasing order
SELECT *,
RANK() OVER (
PARTITION BY career_id
ORDER BY fellowship DESC)
FROM college.students;
-- Get the index of the current tuple in the frame of career
-- in decreasing order
-- and sort the output --
SELECT *,
RANK() OVER (
PARTITION BY career_id
ORDER BY fellowship DESC
) AS brand_rank
FROM college.students
ORDER BY career_id, brand_rank;
-- Where inside the query --
SELECT *,
RANK() OVER (
PARTITION BY career_id
ORDER BY fellowship DESC
) AS brand_rank
FROM college.students
WHERE brand_rank < 3
ORDER BY career_id, brand_rank;
-- Filtering where in subquery --
SELECT *
FROM (
SELECT *,
RANK() OVER (
PARTITION BY career_id
ORDER BY fellowship DESC
) AS brand_rank
FROM college.students
) AS ranked_fellowships_por_carrerra
WHERE brand_rank < 3
ORDER BY brand_rank;
|


